SCL-1 From Lock Implementation to Lock Opportunities
Traditional Locks
Atomic Instructions
xchg
xchg(int *addr, int newVal) returns the old value in addr, and stores the new value into the addr.
Here is the equivalent C code:
int xchg(int *addr, int newVal)
{
int old = *addr;
*addr = newVal;
return old;
}
CompareAndSwap
CompareAndSwap(int *addr, int expected, int newVal) returns the value in the addr, and stores the newVal only if the value equals the expected value.
Here is the equivalent C code:
int CompareAndSwap(int *addr, int expected, int newVal)
{
int actual = *addr;
if (actual == expected)
*addr = newVal;
return actual;
}
CompareAndSwap can also be called a test-and-set atomic operation.
FetchAndAdd
FetchAndAdd(int *addr) atomically increments the value in the address and return the old value.
Here is the equivalent C code:
int FetchAndAdd(int *addr)
{
int old = *ptr;
*ptr += 1;
return old;
}
Linux Equivalent Atomic Instruction
On Linux, some of the implementations are different, but the overall logic is still the same.
atomic_increment and atomic_decrement
atomic_increment(int *addr) and atomic_decrement(int *addr) atomically increase and decrease the value at the addr.
atomic_bit_test_set
atomic_bit_test_set(int *addr, int bit) works like xchg with new value 1. But this operation works on a specific bit specified by bit argument.
exchange_and_add and atomic_add_zero
exchange_and_add(int *addr, int value) is a different operation, it adds value to *addr, and return old value in addr.
Using exchange_and_add, a new atomic operation can be created: atomic_add_zero(int *addr, int value)
This operation Convert hex value to a proper int. Use negative of value. Compare result of exchange_and_add to negative of value, as return result.1
For example:
- The value at
memis 0x80000000 (1000 0000 0000 0000 0000 0000 0000 0000), thenewValis 0x80000000 (1000 0000 0000 0000 0000 0000 0000 0000). Anatomic_add_zero(mem, newVal)is performed.atomic_exchange_and_add(mem, newVal)will be execute, value atmemwill be added with 0x80000000 (0x80000000 + 0x80000000 = 0).- The
newValwill be negate (-0x80000000 = 0x80000000) and compared with original value inmem(0x80000000). - Since 0x80000000 = 0x80000000, result will be true.
- The value at
memis 0x80000001 (1000 0000 0000 0000 0000 0000 0000 0001), thenewValis 0x80000000 (1000 0000 0000 0000 0000 0000 0000 0000). Anatomic_add_zero(mem, newVal)is performed.atomic_exchange_and_add(mem, newVal)will be execute, value atmemwill be added with 0x80000000 (0x80000001 + 0x80000000 = 0x00000001).- The
newValwill be negate (-0x80000000 = 0x80000000) and compared with original value inmem(0x80000001). - Since 0x80000000 = 0x80000001, result will be false.
Remember, these two examples will be used latter in Linux futex lock.
Spin Lock
Using xchg and CompareAndSwap, there are two ways to implement spin locks.
xchg Implementation
typedef struct __lock_t
{
int flag;
} lock_t;
void init(lock_t *lock)
{
lock->flag = 0;
}
void acquire(lock_t *lock)
{
// Spin wait.
while (xchg(&lock->flag, 1) == 1);
}
void release(lock_t *lock)
{
lock->flag = 0;
}
The reason why xchg(&lock->flag, 1) == 1 can spin wait until the lock is available is that xchg is an atomic operation. When lock->flag is 0, the lock is available, xchg will return 0, and the program will exit while loop. The lock is acquired, and the flag is set to 1 so other threads cannot acquire the lock.
When lock->flag is 1, xchg will return 1, and while loop will continue executing. The thread is spin waiting.
In the second scenario, although xchg will write a new value into the lock, nothing will change. The original value is 1 and the new value written into the lock is still 1. Thus, the behavior is expected.
CompareAndSwap Implementation
The only implementation difference between CompareAndSwap and xchg is the acquire process:
void acquire(lock_t *lock)
{
// Spin wait.
while(CompareAndSwap(&lock->flag, 0, 1) == 1);
}
The overall effect is the same for CompareAndSwap implementation. But the value is not written to the address when the flag is not set to 1.
Ticket Lock
The problem of spin lock is obvious, one thread keeps acquiring the lock can stave other thread. Thus, a queue-like structure should be introduced to solve this problem.
A simple implementation is ticket lock. Using two integers, threads can acquire the lock in a certain order. It is less possible for a single thread to use all the resources.
The simplified implementation looks like this:
typedef struct __lock_t
{
int ticket;
int turn;
}lock_t;
void lock_init(lock_t *lock)
{
lock->ticket = 0;
lock->turn = 0;
}
void acquire(lock_t *lock)
{
int myturn = FetchAndAdd(&lock->ticket);
// Spin wait.
while (lock->turn != myturn);
}
void release(lock_t *lock)
{
// Atomic version of lock->turn++
FetchAndAdd(&lock->turn);
}
The way ticket locks keep track of acquire order is to give each thread a turn. When current thread release the lock, the turn variable inside lock data structure will be increase atomically. And next thread with the corresponding turn will be able to acquire the lock.
More Optimization
It is obvious that basic spin locks and ticket locks are still use spin waiting to wait for available lock usage. To better optimize performance, thread should be blocked by the OS when it cannot acquire the lock it wants. And OS should awake the thread when the lock is released by current thread.
One way to achieve similar effect is using yield to give up current running time slice. However, this will still waste time on context switches. The best way to implement such lock should use a thread queue with park and unpark system call2.
Linux Futex Implementation
Combining different advantages and disadvantages, Linux implements a lock with wait queue called Futex lock (fast user-space locking).
Futex lock only use a single int value as the lock, at the same time, it is not only able to keep track of current lock status but also how many threads are waiting for the lock.
mutex_lock
void mutex_lock (int *mutex)
{
int v;
/* Bit 31 was clear, we got the mutex. (this is the fastpath). */
if (atomic_bit_test_set (mutex, 31) == 0)
return;
atomic_increment (mutex);
while (1)
{
if (atomic_bit_test_set (mutex, 31) == 0)
{
atomic_decrement (mutex);
return;
}
/* We have to wait now. First make sure the futex value we are monitoring is truly negative (locked). */
v = *mutex;
if (v >= 0)
continue;
futex_wait (mutex, v);
}
}
When locking, futex lock look specific to the 31 bit (highest bit) of the integer. If it is 1, the lock is currently being acquired. Otherwise, it is release.
Thus, if (atomic_bit_test_set (mutex, 31) == 0) return; set the 31 bit of the lock to 1, and check if the old value is 0.
If the above check failed, the 31 bit of the lock was already 1. In other words, the lock was being acquired. Current thread must append itself to the waiting queue. To do so, the mutex lock is atomically incremented. The last 31 bits of mutex should be the number of threads waiting for the same lock.
A while loop is being used to keep trying to block current thread.
Inside the while loop, the 31 bit is checked again to see if any thread released the lock during the loop.
If any thread released the lock, atomic_bit_test_set should return 0. And current thread acquire the lock successfully. The mutex variable should be decrement as current thread is no longer in the waiting queue.
Otherwise, futex_wait syscall is used to send current thread to sleep state. Note that before futex_wait, variable v is used to check if current mutex value is still negative. This is because the 31 bit of mutex will be 1 (mutex will be negative) if the lock is still acquired. If v >= 0, the lock is no longer busy. Current thread should go to next loop to try to acquire the lock.
When calling futex_wait, v is also used as an expected value to compare with current mutex value. This is because if there’s a context switch between if (v >= 0) and futex_wait (mutex, v), another thread can change the mutex value. If the real mutex value is not equal to v, futex_wait syscall will return immediately and next loop will be executed3.
mutex_unlock
void mutex_unlock (int *mutex)
{
/* Adding 0x80000000 to the counter results in 0 if and only if there are not other interested threads - we can return (this is the fastpath). */
if (atomic_add_zero (mutex, 0x80000000))
return;
/* There are other threads waiting for this mutex, wake one of them up. */
futex_wake (mutex, 1);
}
The mutex_unlock function use atomic_add_zero to check if there’s any other thread waiting for current mutex. First, it should be acknowledged that the 31 bit of current mutex is 1. Since the lock should be acquired to call the unlock method. Then, adding 0x80000000 will only change the highest bit to 0, which release the lock.
Then, the added value should be tested to be 0. If mutex value after adding 0x80000000 is 0, no thread was waiting for the lock. Otherwise, at least one thread is waiting for the lock.
In the first case, the unlock function can return immediately. In the second case, futex_wake syscall is used to wake one waiting thread listening to address mutex. It cannot be guaranteed that which thread is awake at first. The queue is managed completely by the OS. And a waiter with a higher scheduling priority is not guaranteed to be awoken in preference to a waiter with a lower priority3.
Fairness Problem (Require Further Research)
I believe that it is possible for a thread to cut in line before other wait threads in the queue. In other words, although the futex lock can guarantee the mutual exclusion, it cannot guarantee that threads acquiring the lock latter will not get into the critical section early.
In one example, the waiting thread number is not 0 (mutex = 0x80000001 for example). Thread T0 is currently holding the lock, thread T1 is waiting for T0 to release the lock.
Now, T0 release the lock, calling mutex_unlock. if (atomic_add_zero (mutex, 0x80000000)) is executed, and the result is apparently not 0, so it is not returned immediately.
However, a context switch happened. T2 is not scheduled, and T2 called mutex_lock to acquire the lock. When T2 execute if (atomic_bit_test_set (mutex, 31) == 0) the result should be true. Since T0 use atomic_add_zero to reset the 31 bit to 0 when releasing the lock. As a result, T2 use fastpath to acquire the lock earlier than T1, although T1 is waiting longer than T2.
I’m not sure if this is an expected behavior. Or, the fastpath, by design, is used to provide such quick acquire action and save the resource to perform extra context switches.
Scheduler Subversion and Lock Opportunity
Scheduler Subversion
According to Yuvraj Pate4, modern locks can lead to scheduler subversion issue since when two process are acquiring the same lock, the one who hold the lock for a longer time will get more CPU resource.
In the example of mutex lock, one thread T0 can completely starve T1, since the non-critical section time is so short that T0 can immediately acquire the lock once it release it.
Lock Opportunity
In the paper, a variable called Lock Opportunity (LOT) is introduced to measure how many CPU resource one thread use for a lock.
\[LOT(i) = \sum Critical \_ Section(i) + \sum Lock \_ Idle \_ Time\]The author mentioned that when the lock is acquired by one thread, no thread have the opportunity of acquiring the lock beside the thread it self. When a lock is idle, any thread have the opportunity to acquire the lock.
For 4 examples given in the article, lock opportunities for each thread can be calculated:

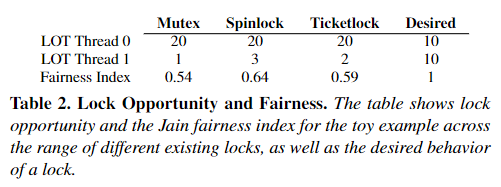
In the table, Jain’s fairness index is calculated. This index is based on following formula.
\[FairnessIndex = \frac{(\sum x_i)^2}{n \sum x_i^2}\]Where $x_i = T_i/O_i$ and $T_i$ is the LOT for current thread, $O_i$ is the sum of LOT for all threads.
For example, in Mutex column, T0 have LOT of 20, T1 have LOT of 1
\[FairnessIndex_{Mutex} = \frac{(\frac{20}{21} + \frac{1}{21})^2}{2 * ({\frac{20}{21}}^2 + {\frac{1}{21}}^2)} = 0.54\]From this table, it is clear that most modern locks are unfair, while desired lock is completely fair.