Notes - SPGrid - A Sparse Paged Grid structure applied to adaptive smoke simulation
Original Paper
SPGrid: A Sparse Paged Grid structure applied to adaptive smoke simulation
Introduction and Related Works
In fluid simulations, sparse data structures are widely used for spatial adaptations. Previous solutions include CSR grids, oct-trees, and H-RLE level set. Some more recent studies also used OpenVDB, a B+ tree-like data structure.
Methods such as CSR grids and oct-trees may suffer from low cache hit rates and, therefore, experience lower computational bandwidth than the theoretical one.
SPGrid also stores sparse data with a minimal memory footprint while maintaining a relatively high memory throughput for both sequential and stencil access. The most important contribution to this work is the hardware acceleration for sparse uniform grids. Each geometric block occupies one memory page. Therefore, the accessed blocks can be cached in TLB.
SPGrid can be compared with another sparse data structure: OpenVDB. According to the authors, “Both SPGrid and VDB seek to accelerate sequential and stencil access. SPGrid places an even higher emphasis on optimizing throughput, especially in a multithreaded setting, to levels directly comparable with dense uniform grids.” This shows that the hardware TLB cache may be faster than the software caches OpenVDB uses regarding memory throughput.
The comparison between SPGrid and OpenVDB is shown in Table 1.
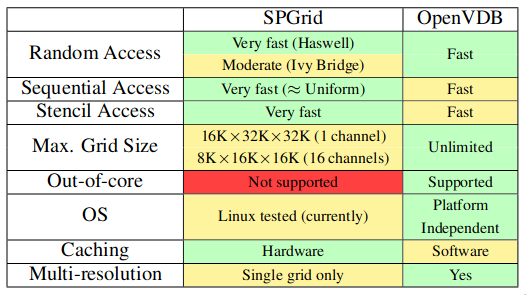
For SPGrid, the maximum grid size is limited. However, 16Kx32Kx32K resolution should far exceed normal sparse computation requirements. Moreover, similar to OpenVDB, a hash map of SPGrids may be used to support a larger sparse structure.
SPGrid Implementation Details
The two most essential access patterns of SPGrid are sequential access and stencil access. As mentioned in the paper, truly random sparse grid access is uncommon. Therefore, this paper mainly aims to solve two aforementioned access patterns.
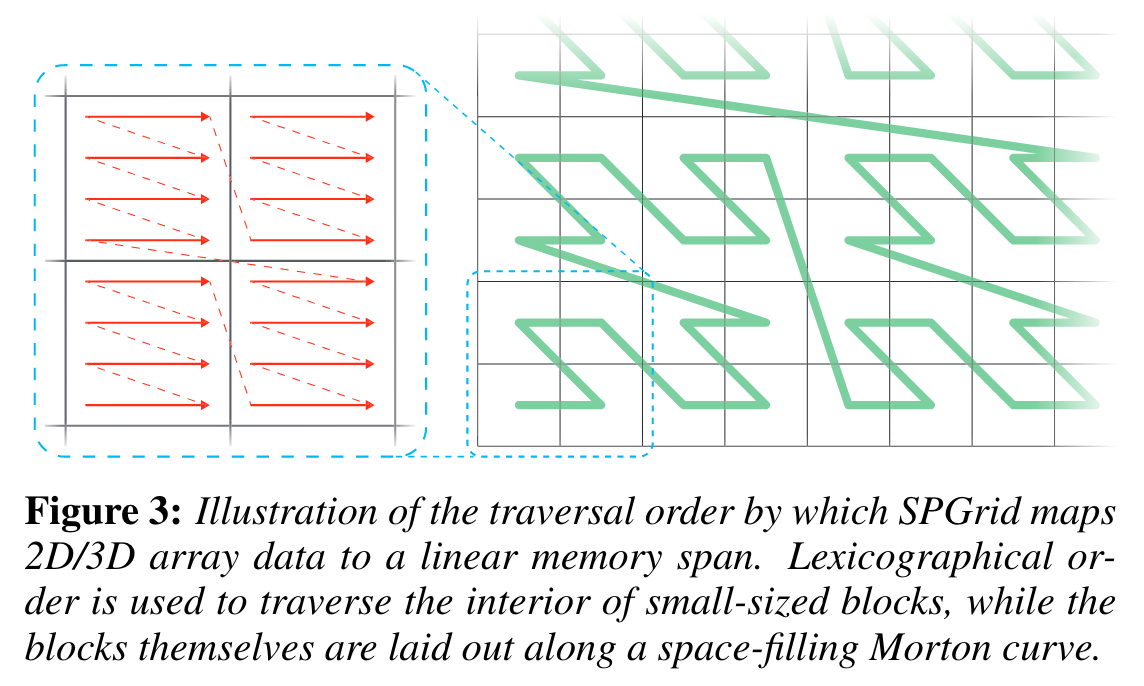
The basic building block for SPGrid is a geometric block, which takes 4 KB in general. Data are stored in lexicographical order inside each geometric block.
The geometric blocks are traversed using the Morton curve. According to the paper, this ensures that geometrically proximate blocks will be stored in nearby memory blocks with high probability.
To allocate the entire virtual grid, the author used the mmap API. The theoretical virtual memory limit is 128 TB per process, as the paper mentions. This comes from the x86 architectural limit with a 4-level page table. However, with a 5-level page table, it’s possible to reach up to 64 PB virtual address space.
A detailed architectural memory layout can be found here.
In the paper, the authors used
void *ptr = mmap(0, size, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_NORESERVE, -1, 0);
to allocate a continuous chunk of virtual memory. The reserved addresses represent the virtual grid.
According to the documentation, the mmap API accepts a starting address and an allocation size as the first two arguments.
The third argument marks the permission of the allocated memory. In this case, PROT_READ|PROT_WRITE means the memory can be read and write.
The fourth argument marks the flag of the memory. According to the authors, the flags MAP_PRIVATE|MAP_ANONYMOUS|MAP_NORESERVE instruct the operating system to never swap out any allocated pages. Therefore, all the pages in the virtual address range is either a physical memory resident or has never been touched before.
Operating System Background
To better understand how this mechanism help the SPGrid implementation, we need to review the virtual memory layout of modern computers.
In 32-bit systems, a virtual memory address is composed of a 12-bit offset and 20-bit virtual page number. Each page takes $2^{12} = 4KB$ and the maximum virtual memory address is 4 GB.
In 64-bit systems, virtual memory addresses are not limited by the length of the address but the size of page table. This explained why 5-level page tables allow larger virtual memory address.
To translate virtual addresses to physical addresses, the operating system uses page tables to map virtual page numbers to physical page numbers. Offsets are not translated because memory in the same page are continuous on the physical memory.
Modern computer architectures also introduced Translate Lookaside Buffers (TLB) to accelerate page number translations.
When a memory access instruction is executed, the address is first sent to TLB for physical memory translation. If there’s a TLB hit and the instruction is reading the memory, the CPU will try to find the data in cache. The memory management unity will keep falling back to the next cache level if there’s a cache miss until it reaches the main memory.
If there’s a TLB miss, the MMU will try to translate the memory in the page table. A page table hit will load the translation history to the TLB and read the page. A page table miss will result in a page fault.
In the operating system course I took during college, the page fault can be only caused by swapping. A page fault will trigger the operating system to look for the corresponding page on the swap file on disk. But the page may not even exist if the mmap API is used. In this case, the OS will create a zero-initialized page on the memory.
Address Arithmetic
SPGrid uses a special address encoding to traverse the data in Morton curve. The lower bits inside a memory page is encoded in the traditional C++ n-dimensional array. The higher bits are computed by interleaving the Cartesian coordinate.
This memory encoding technique also supports storing multiple channels of data in the same SPGrid. In the original paper, channel data is stored in the geometric blocks. While each geometric block takes 1 page, a lagrer channel size will makes the lexicographical size of the geometric block smaller.